I’ve threatened to come out of blog retirement for a long time but in the triage of Hope’s life, it just never happened (outside a few posts for SQLStarter track). Now that COVID 19 has upended travel for both work and SQL community events, seems the time has found me. And also not that I seriously thought my blogging again would trigger some terrible apocalypse like zombies or Godzilla showing up, but when better to do it than in 2020 when folks may not even notice?
So what’s got me writing besides more time? I’ve been helping customers at Microsoft with data challenges of all sizes for the past 5 years with the last 1.5 focused on the Education sector. A lot of my job is helping folks figure out and implement data things in Azure. If I think something is harder to do, I tend to try to help automate it in some way. I’ve built up a lot of scripts, how to information, and a billion links to info over the years but I haven’t been great about putting it out in the world. So here’s my attempt at fixing that with the help of some better Git/Github skills (thanks again Drew).
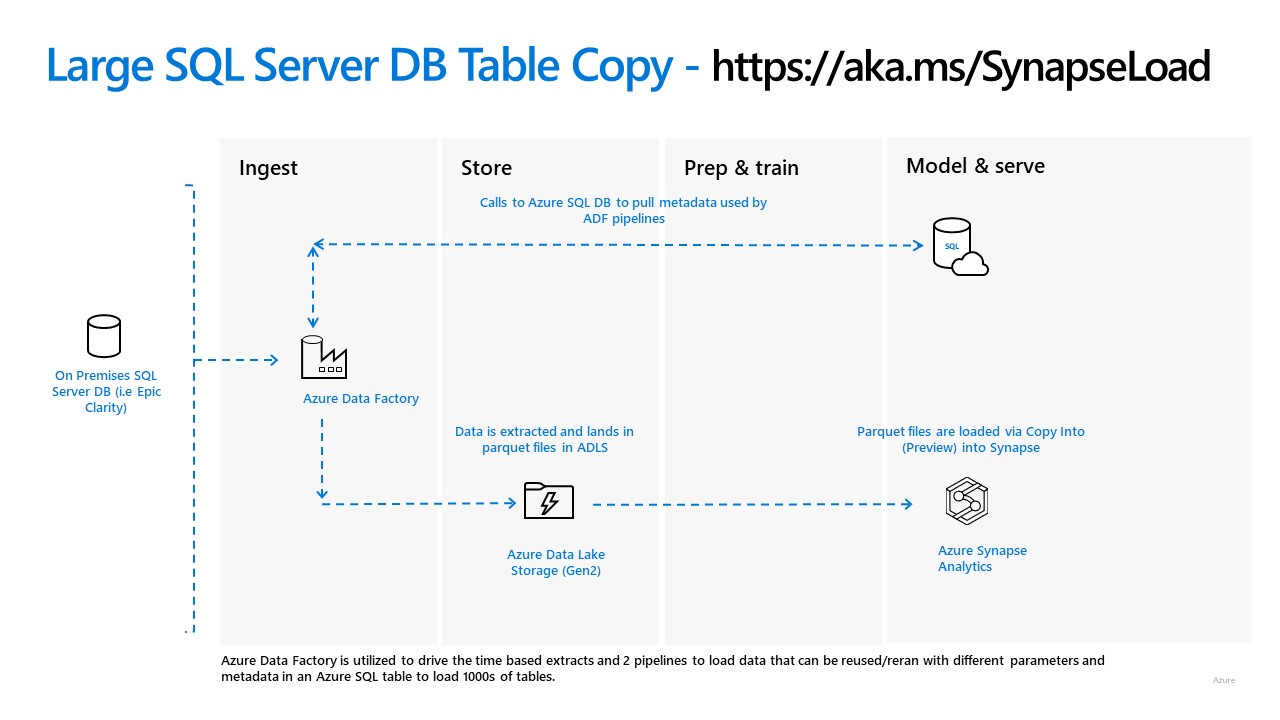
So what’s the hard thing I want to help make easier in this post? Metadata driven pipelines in Azure Data Factory! I had the opportunity awhile back to work with a customer who was pulling data out of large SQL Servers to eventually land data into Azure Synapse SQL pools back when they were still Azure SQL DW. We created a couple load pattern pipelines that used metadata in Azure SQL DB to load Synapse sql pool tables from parquet files in Azure Data Lake Storage (ADLS) Gen 2.
Not gonna lie, the pipelines weren’t easy for me to learn to setup initially. Big thanks to Catherine for your blog which was a life preserver in the hardest parts! So I wanted to see if I could automate it in my old friend PowerShell. That grew into what is now published out on https://aka.ms/SynapseLoad. This is the bones to create all the pieces in Azure (diagram below) including the ADF pipelines. I intend to keep that solution as all the pieces are using GA (general availability) Azure Data Services.
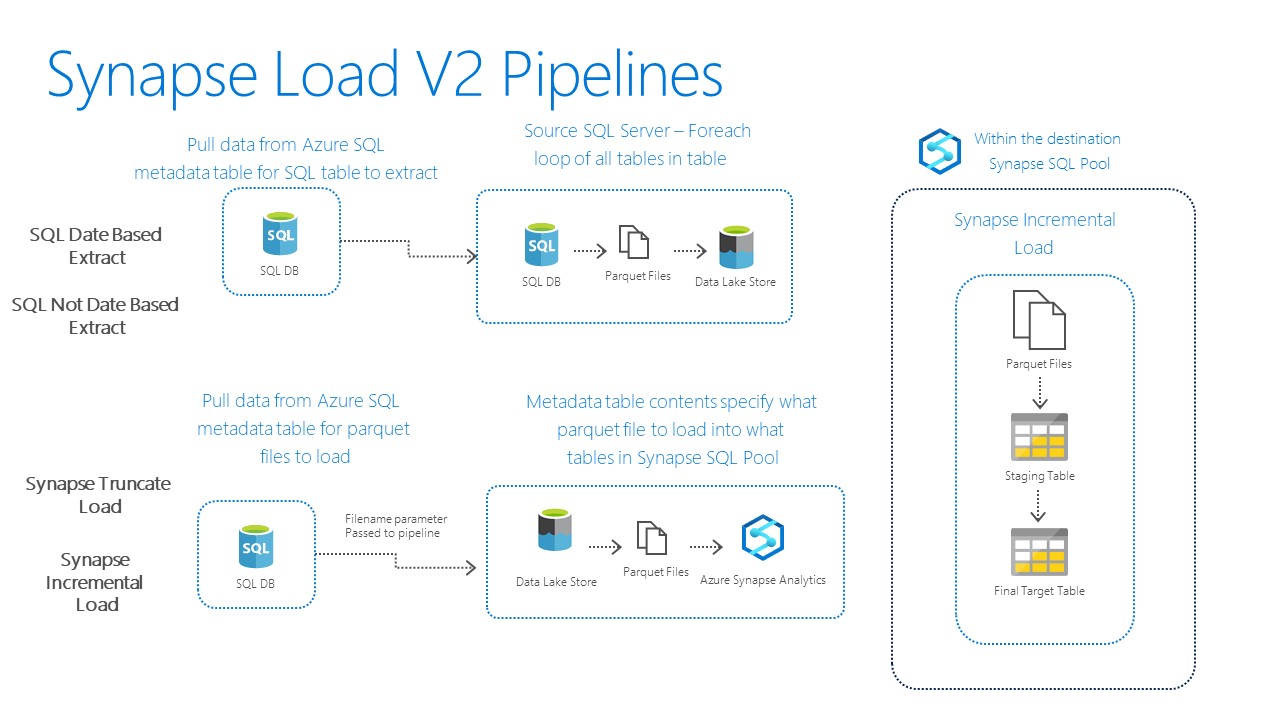
I also have a new incarnation of that work out now as well. The new solution is using as much of the new Synapse Preview workspaces that PoSH cmdlets would allow (no pipelines in workspace yet). I also have some additional pipelines to drive the extraction of SQL tables to parquet files in ADLS. These pipelines can extract portions from date based criteria or other non date columns using metadata too. Oh and I also threw in some custom logging back to Azure SQL DB as well. This version can be found at https://aka.ms/SynapseLoadV2.
I hope to make this better each time I work with a customer. I have a laundry list of updates in mind already like adding the extract pipelines to the GA version. If you use it, and have suggestions, issues, or just find it helpful throw out a tweet to me using hashtag #HopeSynapseLoad
