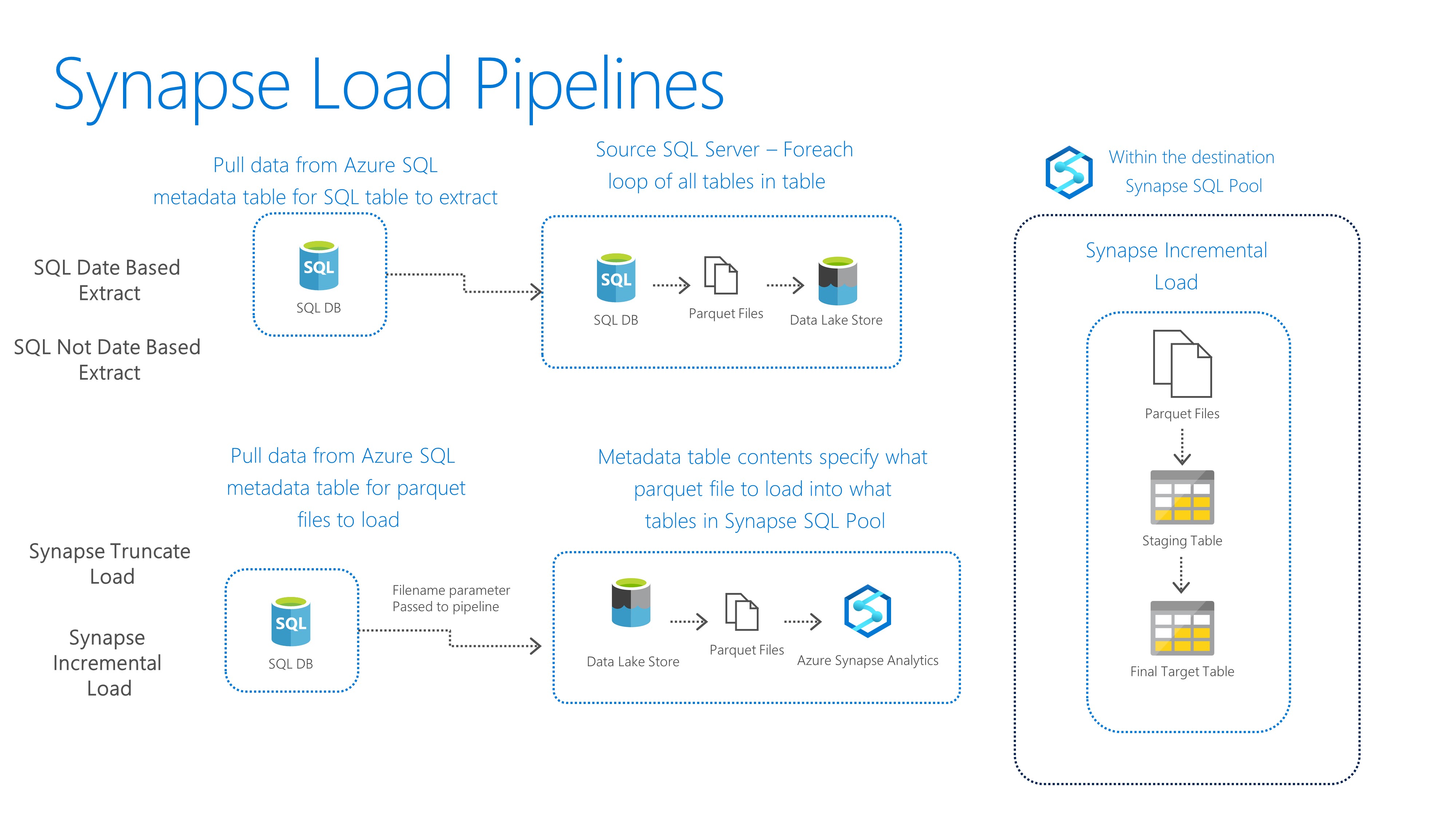
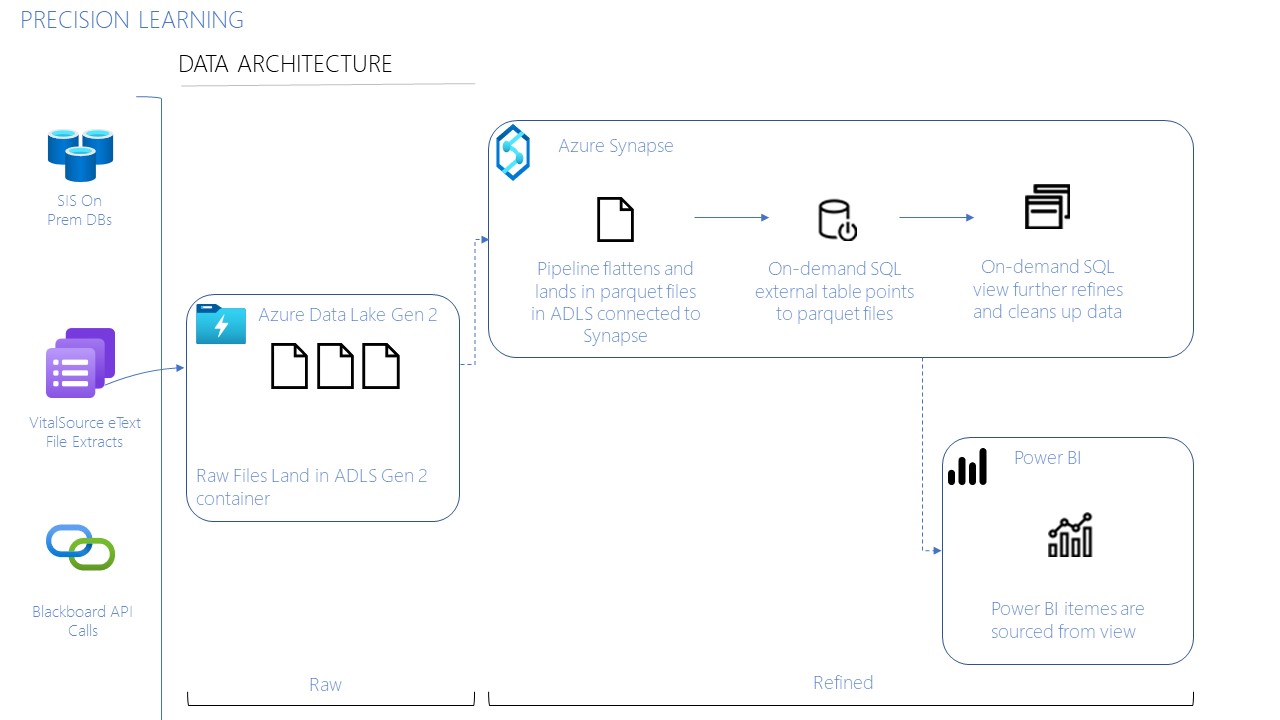
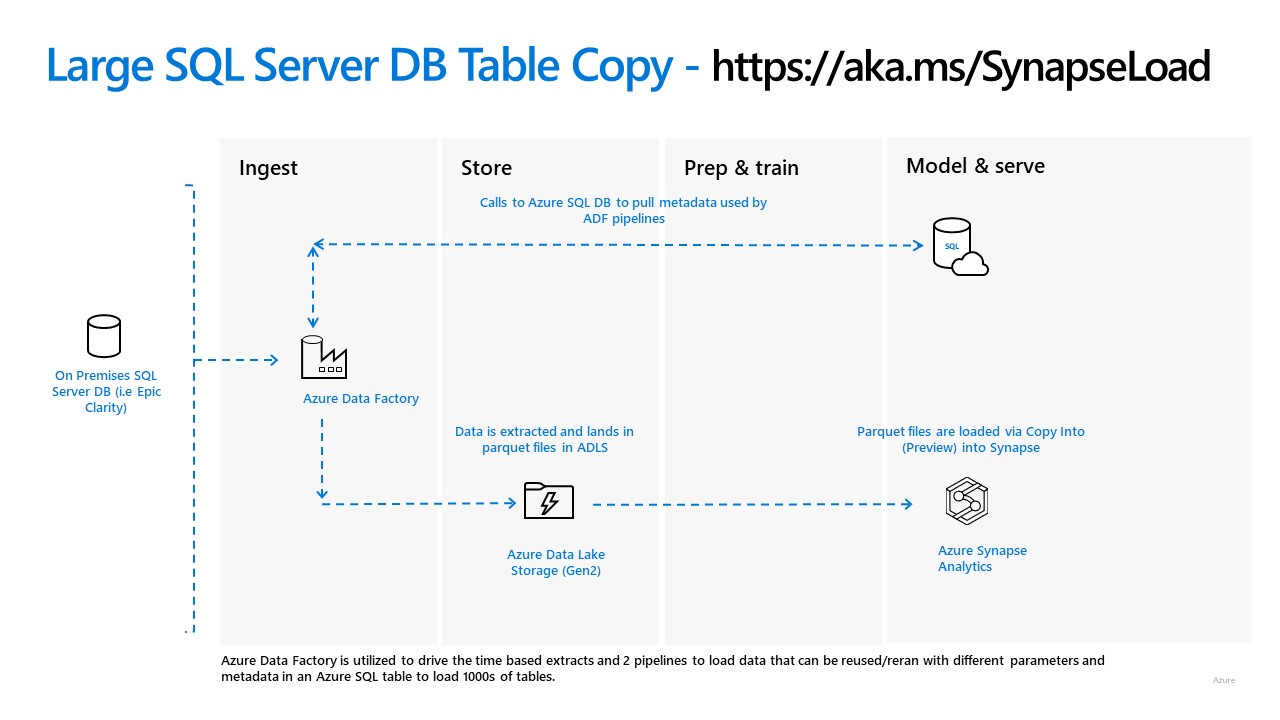
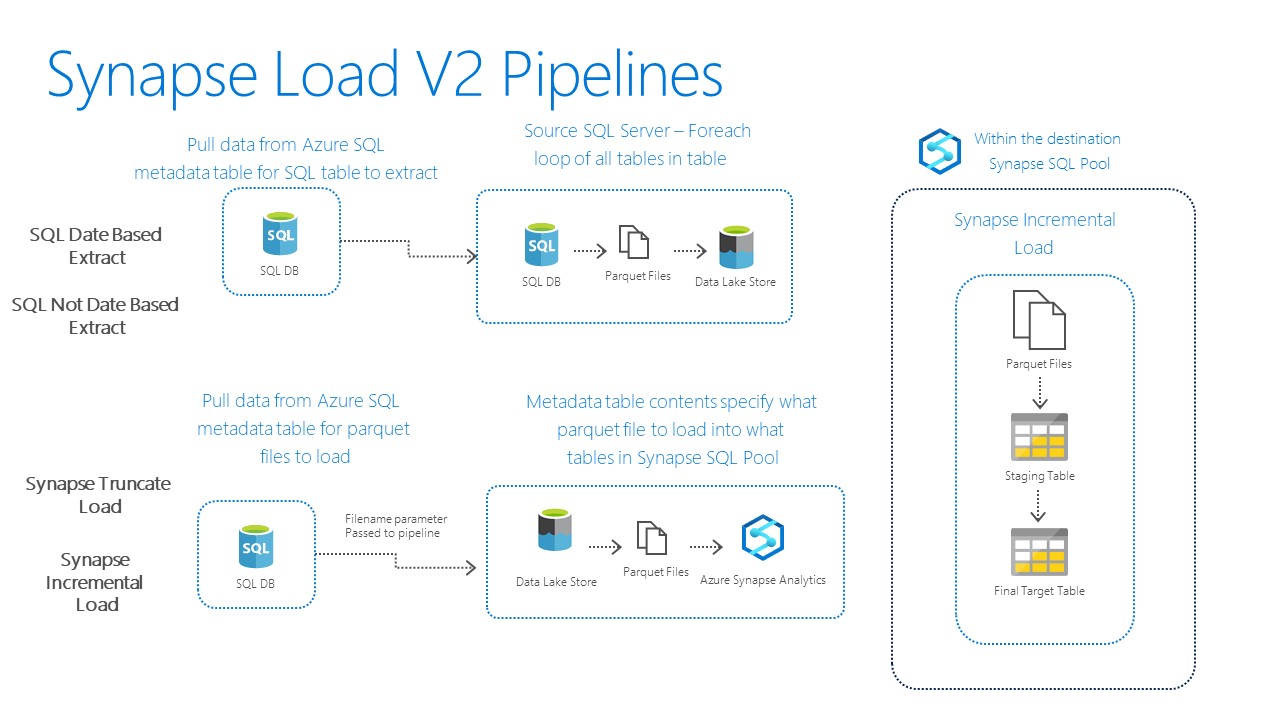
I’m back home from PASS Summit 2015 and reflecting on the experience. I think I even still have a little bit of the goofy grin that I couldn’t wipe off my face all week. I do so love PASS Summit! This was my 5th consecutive one. I went back and looked through some of my previous blog posts and I still have all the same giddy, giggling idiot feelings I have had all these years. Below are my top 10 highlights of this year’s PASS Summit.
***
10. Calories don’t count at PASS Summit – Ok this isn’t really true but I pretended it did. After I had an egg white omelet at breakfast the first day, it was all downhill from there. It’s difficult to eat well at a conference and I missed eating like a truck driver so I took a healthy eating sabbatical while there. The Morning After burger at Tap House is very good by the way.

My egg white omelet was at one of the “hey pull up a chair” breakfasts at Daily Grill.
9. Great Sessions – As with every Summit, I didn’t catch as many sessions as I would have liked (highly recommend purchasing DVD/download of sessions for this reason). I did catch my dear friend, Mark Vaillancourt’s (Twitter | Blog) session “A Bigger Boat: Data Visualization Lessons from the Movie Theater”. Mark always cracks me up and I always enjoy his sessions. Great information on perception with the right balance of humor mixed in to it.

Mark caught a fish this big!
I also caught Kasper de Jonge’s (Twitter | Blog) session “The Analysis Services Evolution”. Poor Kasper had all the presentation planets align against him. He couldn’t get the screen to display except setting up like he is in the picture below. He handled all the issues VERY well and it was a great session. Folks were excited to hear of the new features in SSAS so that helped too.

Poor Kasper!
8. Birds of a pitiful feather – On Friday they had the Birds of a Feather lunch. This is where they will setup tables with specified subjects. It’s always nice for good discussions. I went with my friend and former co-worker, Meagan Longoria (Twitter | Blog) . I was thinking I would sit at the Datazen table but turned out there wasn’t one. I did find a table though on geo-spatial. There were only a couple folks sitting there at the time so we sat there. After chatting with them for a couple minutes, they left and Meagan and I manned that table together alone (cue the All By Myself song). We had fun but that was a lonely subject table(reason I said pitiful)! The whole Birds of a Feather lunch seemed to be scaled down a bit more than in years past too.

The masses at the WIT Luncheon
I also missed the lunch where they setup tables for regions. I always met new people at each lunch from my area who weren’t familiar with the local user group. I’ve connected with several folks over the years at that lunch. Not sure of others experience but I missed it.
***
7. SQL Mystery – Doug Lane (Twitter | Blog) is a brave man! He had a couple of sessions at Summit where he uses other speakers as cast members in his sessions. It’s like incorporating community theater into his technical sessions. I was asked to be a cast member in “SQL Server Mystery: Dead Reports Don’t Talk”. He sent the script several days ahead of time but I was more nervous about this than my technical session. I feel I do well with conversations. I feel I do well in a rehearsed technical setting. Anything off the cuff, in front of an audience, yeah not so much. That and I hated the thought of me impacting his Summit session if I messed up. I survived but definitely could have done a better job. Sorry Doug!

Doug’s super fun SSRS Mystery session
6. Kasper knowing who I was and said looked through my session slides! – I still get star struck at PASS Summit. I was introduced to Kasper and he had a question about one of MY slides! I am still giddy about that!
***
5. Tim Chapman is a helluva guy! – Knowing I was new to Microsoft, Tim (Twitter ) reached out and pointed me to great resources to help navigate the oodles of tools and info within Microsoft. Not only that but he introduced me to some great folks at Summit. Thank you much Tim! Very much appreciate it!
***
4. Speaker Idol – I was asked by Denny Cherry (Twitter | Blog) if I would be a judge in this year’s Speaker Idol. For those unfamiliar, it is a contest for speakers to win a speaking slot at the next year’s Summit. I said yes and was very glad to be a part of it and honored to be in the line up of judges (Mark Simms (Twitter), Andre Kamman (Twitter | Blog), Allan Hirt (Twitter | Blog), Joey D’Antoni(Twitter | Blog), and Karen Lopez (Twitter | Blog)). All of the speakers were great! Due to that, it came down to getting way nit picky on the tiniest of details of the sessions. I felt little uncomfortable doing that since many of the speakers I consider friends. Still was a great process to be a part of and I picked up some tips for myself as a speaker. The winner was David Maxwell (Twitter | Blog) . Congrats David!

No Summit trip is complete without a trip to Bush Garden. Many times it’s Jason twisting my arm to go 🙂
3. Marco Russo / Alberto Ferrari in my session – My session was over SSAS Tabular performance. I reference Marco Russo (Twitter | Blog) and Alberto Ferrari (Twitter | Blog) many times during it. During practice run throughs of my session, it dawned on me that this was the only time I would give the session and they could show up. Guess what?! They came to MY session!! That still cracks me up a bit and was great to meet them in person.
***
2. Seeing all my #SQLFamily all week – One of the best parts of Summit is that you can’t throw a rock all week and not hit a member of #SQLFamily. Over the years I have met so many wonderful SQL people from all over the world. Summit is the one time of year when the majority of those folks are together. Makes me feel all SQL warm and fuzzy just thinking about it.

My favorite pic of Summit!
- Stephanie Bruno moment – I help babies in Africa! – I went to dinner with a group on Thursday evening at Tap House. I met Stephanie Bruno (Twitter) a couple years ago when she attended my spatial data session. We became friends that year and kept up some after that Summit. She works for the Elizabeth Glaser Pediatric AIDS Foundation (www.pedaids.org). She was at that dinner and began talking about how I helped her with some Datazen work she was doing. And by this act of me getting information to her, I was also in a way helping babies in Africa! I get teary eyed again just thinking about it. I mean we speak and hope some bit of info we relay helps folks do their jobs or helps them with an issue they run into but that’s usually the end of the thought. It really hit me in the gut to be able to draw a line to a concrete example of something I did, doing some real good in the world! One session, one connection did that! It’s really amazing to think about and helps push more passion into my speaking in the community, my push to drive new speakers, and my push to get folks to become part of this amazing community!